Docker est un logiciel libre qui automatise le déploiement d'applications dans des conteneurs logiciels s'executant en isolation. Un conteneur Docker, à l'opposé de machines virtuelles traditionnelles, ne requiert aucun système d'exploitation séparé et n'en fournit aucun mais s'appuie plutôt sur les fonctionnalités du noyau et utilise l'isolation de ressources ainsi que des espaces de noms séparés pour isoler le système d'exploitation tel que vu par l'application.

SLURM (Simple Linux Utility for Resource Management) est une solution open source d'ordonnancement de tâches informatiques qui permet de créer des grappes de serveurs sous Linux ayant une tolérance aux pannes, type ip-failover, ferme de calcul, système d'ordonnancement des tâches.
Cette solution peut être utilisée sur des grappes de tailles variées, de deux à plusieurs milliers de serveurs. Il est utilisé sur la majorité des plus puissants supercalculateurs de la planète.
source: https://fr.wikipedia.org/wiki/SLURM

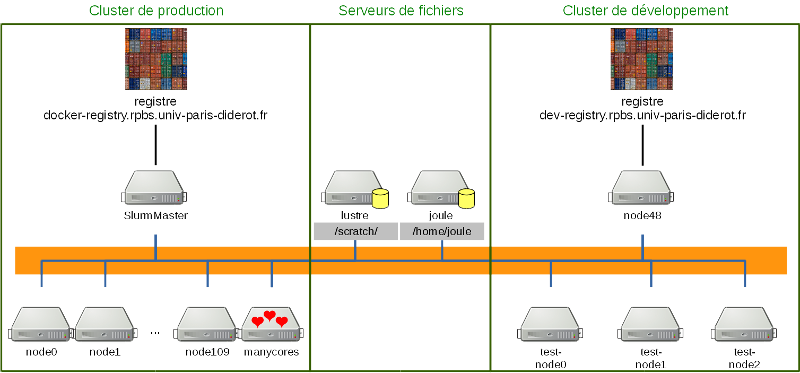
Parallèlement à la ressource de calcul, la plate-forme dispose également de 4 serveurs de virtualisation permettant d'héberger des serveurs Web ou des bases de données. Voir le paragraphe Politique de déploiement de services.
La ressource de calcul est constituée d'une ferme hétérogène de nœuds :
Les utilisateurs du cluster de calcul ont accès à deux espaces de stockage :
| Chemin | Type | Accessible depuis | Utilisation | Performance | Sauvegardé |
|---|---|---|---|---|---|
| /home/joule/ | NFS | nœuds de calcul | espace de stockage | moyenne | oui |
| /scratch/user/ | Lustre | nœuds de calcul + conteneurs logiciels | espace de travail | élevée | non |
Il existe plusieurs façons de se connecter à la ressource de calcul :
Le serveur de noms est hébergé sur la machine Annuaire (172.27.7.52). Pour l'utiliser, il existe plusieurs solutions selon la version de votre système.
Cliquer sur l'icône de Network Manager dans la barre en haut à droite -> Edit Connections -> Onglet Wired -> Onglet IPv4 Settings et entrer 172.27.7.52 dans le champ DNS servers. Cliquer sur Save...
Éditer le fichier /etc/resolv.conf avec les droits root et y ajouter les lignes suivantes :
nameserver 172.27.7.52 nameserver 194.254.200.25 nameserver 194.254.200.26
La plupart du temps cette solution n'est pas viable car un certain nombre de services écrasent le fichier (NetworkManager, dhcpd ou resolvconf).
Désactiver le démon NetworkManager :
sudo systemctl stop NetworkManager sudo systemctl disable NetworkManager
Encore une fois, plusieurs possibilités selon la nature de votre système :
Éditer le fichier /etc/network/interfaces et y ajouter les lignes suivantes (remplacer eth0 par le nom de votre interface) :
auto eth0 iface eth0 inet dhcp
Éditer le fichier /etc/dhcp/dhclient.conf et y ajouter la ligne suivante :
prepend domain-name-servers 172.27.7.52;
OU
Éditer le fichier /etc/sysconfig/network-scripts/ifcfg-eth0 (remplacer eth0 par le nom de votre interface) et modifier / ajouter la ligne suivante :
DNS1=172.27.7.52
Pour se connecter au cluster de production :
ssh login@slurmmaster.rpbs.priv
Pour se connecter au cluster de développement :
ssh login@node57.rpbs.priv
Éditer le fichier /etc/hosts avec les droits root et y ajouter les lignes suivantes :
172.27.7.35 slurmmaster #cluster de prod 172.27.7.57 node57 #cluster de dev
Il est bien-sûr possible de remplacer ces alias par d'autres (par exemple cluster et clusterdev respectivement).
172.27.7.35 slurmmaster docker-registry.rpbs.univ-paris-diderot.fr dev-registry.rpbs.univ-paris-diderot.fr
Pour se connecter au cluster de production :
ssh login@slurmmaster
Pour se connecter au cluster de développement :
ssh login@node57
Pour des raisons de sécurité, les conteneurs logiciels ne montent que l'espace de travail de l'utilisateur (/scratch/user/). Il faut donc s'assurer d'être dans le bon dossier avant de soumettre toute commande :
cd /scratch/user/[LOGIN]
Exemple :
cd /scratch/user/rey
La liste des partitions disponibles peut être consultée avec la commande suivante :
sinfo --summarize
Exemple qui permet d'obtenir le nombre de cpus et de gpus pour chaque nœud de la partition gpu :
sinfo -p gpu --Node -o "%6t %6z %.4c %16G %6m %N"
Pour plus de paramètres :
man sinfo
La commande de base pour soumettre un job en intéractif est la suivante :
srun [OPTIONS] [COMMANDE À EXÉCUTER]
Pour exécuter un programme dans un conteneur docker :
drun [NOM DE L'IMAGE] [COMMANDE À EXÉCUTER]
Pour soumettre un job avec un exécutable contenu dans une image, on doit donc combiner les deux commandes :
srun drun [NOM DE L'IMAGE] [COMMANDE À EXÉCUTER]
Exemple :
srun drun faf-drugs python /usr/local/FAF-Drugs/bin/FAFDrugs.py -D 103_c.sdf -f drug -p xlogp3 -g --painsa --painsb --painsc --regular
Pour spécifier la partition à utiliser (par défaut, production) :
srun -p bigmemory drun [NOM DE L'IMAGE] [COMMANDE À EXÉCUTER]
Allouer un nombre de cpu(s) pour le job :
srun -c 8 drun [NOM DE L'IMAGE] [COMMANDE À EXÉCUTER]
Il faut obligatoirement soumettre les jobs sur une partition gpu et indiquer le nombre de GPUs à utiliser avec l'option --gres :
srun -p newgpu --gres=gpu:1 drun [NOM DE L'IMAGE] [COMMANDE À EXÉCUTER]
La commande nvidia-smi permet de vérifier la correcte allocation des GPUs :
rey@SlurmMaster:~$ srun -p newgpu --gres=gpu:2 drun gromacs-plumed nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.33.01 Driver Version: 440.33.01 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce RTX 208... On | 00000000:03:00.0 Off | N/A |
| 24% 31C P8 19W / 257W | 0MiB / 11019MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 GeForce RTX 208... On | 00000000:05:00.0 Off | N/A |
| 25% 26C P8 16W / 257W | 0MiB / 11019MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Exemple de dynamique moléculaire avec gromacs utilisant un GPU :
srun -p newgpu --gres=gpu:1 drun gromacs-plumed gmx mdrun -nsteps 2000 -deffnm 1f3_AE
Pour soumettre des jobs en batch en mode non-intéractif :
sbatch [SCRIPT.Q]
Les mêmes options que la commande srun s'appliquent : ils doivent être précédés par l'instruction #SBATCH dans le script ou bien utilisés en ligne de commande de la même façon que la commande srun.
Exemple de script batch :
#!/bin/bash
#SBATCH --output=test.out
#SBATCH --array=1-5
#SBATCH -p production
case "$SLURM_ARRAY_TASK_ID" in
1) fichier='/scratch/user/rey/protein_1';;
2) fichier='/scratch/user/rey/protein_2';;
3) fichier='/scratch/user/rey/protein_3';;
4) fichier='/scratch/user/rey/protein_4';;
5) fichier='/scratch/user/rey/protein_5';;
esac
drun opendocking babel -i ${fichier}.pdb -o ${fichier}.mol2
Les développeurs disposent également d'une bibliothèque permettant la soumission de jobs directement depuis un script python. Pour l'instant la bibliothèque ne comporte qu'une seule fonction utilisable, mais ceci peut être amené à évoluer. La plupart des fonctions font usage de la bibliothèque python-drmaa pour soumettre des jobs via Slurm.
Exemple simple de script python utilisant la bibliothèque cluster :
#!/usr/bin/env python
import sys # import de la bibliothèque
sys.path.append("/service/env")
import cluster
cmd = "PyPPPExec" # chemin vers l'executable
args = ["-s %s" % self.options.pepseq, # liste d'arguments de type str
"-l %s" % self.options.label,
"--2012",
"-v"]
cluster.runTasks(cmd, args, docker_img = "pep-sitefinder")
Exemple de script python qui va itérer sur une liste contenue dans un fichier :
#!/usr/bin/env python
import sys
sys.path.append("/service/env")
import cluster
cmd = "echo"
args = [ '$(sed -n "${TASK_ID}p" liste.txt)',
]
cluster.runTasks(cmd, args, tasks = 5, docker_img = "opendocking")
Il n'y a plus qu'à executer le script en le soumettant sur le cluster :
srun python example.py
Afficher les jobs en cours d'execution ou en attente :
squeue
Suivre l'exécution des jobs à chaque seconde :
watch -n 1 squeue
Afficher les jobs d'un utilisateur en particulier :
squeue -u rey
Afficher plus de colonnes :
squeue -o '%.18i %.9P %.30j %.8u %.8T %.10M %.9l %.6D %R %q %a'
Obtenir des infos sur un job :
scontrol show job -dd [ID DU JOB]
Annuler un job :
scancel [ID DU JOB]
Annuler tous les jobs d'un utilisateur en particulier :
scancel -u rey
Annuler tous les jobs en attente pour un utilisateur :
scancel -t PENDING -u rey
Il existe plusieurs méthodes pour transférer des données sur l'espace de stockage sauvegardé (Joule) depuis sa machine.
Les utilisateurs de l'espace de stockage sauvegardé doivent me faire une demande avec l'ip de la machine qui va monter le répertoire.
Pour monter le répertoire ponctuellement :
mkdir -p /home/joule/rey sudo mount -o nfsvers=3 -t nfs 172.27.7.56:/home/joule/rey /home/joule/rey
Pour monter le répertoire au démarrage il faut modifier le fichier /etc/fstab et y ajouter la ligne suivante :
172.27.7.56:/home/joule/rey /home/joule/rey nfs defaults,nfsvers=3 0 0
Pour prendre les changements en compte immédiatement :
sudo mount -a
Pour faire une simple copie, on doit passer par la machine SlurmMaster :
scp /home/rey/mon_fichier rey@slurmmaster:/home/joule/rey
Alternativement il est possible de monter son répertoire via sftp ou sshfs. Il faudra alors copier sa clé publique sur SlurmMaster en utilisant la commande ssh-copy-id.
mkdir -p /home/joule/rey ssh-copy-id rey@slurmmaster sshfs rey@slurmmaster:/home/joule/rey /home/joule/rey
Il est possible d'accéder au réseau du laboratoire via ssh depuis une connexion distante. Pour cela, dans un terminal, taper :
ssh [login]@epervier.rpbs.univ-paris-diderot.fr
À partir de cette machine il est possible d'accéder à l'ensemble des machines des réseaux bfa-cmpli (172.27.6.x) et rpbs (172.27.7.x).
Pour tunneliser sa connexion, ouvrir un terminal, taper la ligne suivante :
ssh -L[port_local]:[machine_du_laboratoire]:22 [login]@epervier.rpbs.univ-paris-diderot.fr
Puis laisser le terminal ouvert. Pour se connecter à la machine, ouvrir un nouveau terminal puis entrer :
ssh [login]@localhost -p [port_local]
On peut également se connecter à la machine avec Nautilus (Gnome-shell, Ubuntu, Fedora, etc...) et monter un dossier distant comme si il s'agissait d'un dossier local. Pour cela, faire Ctrl + L puis taper dans la barre d'adresse ssh://[login]@localhost:[port_local]. Cela permet surtout de travailler sur ses fichiers distants avec des programmes qui tournent en local, ce qui est bien moins lourd que d'exporter l'affichage de la machine distante.
Quelques exemples :
ssh -L1234:172.27.6.198:22 rey@epervier.rpbs.univ-paris-diderot.frssh rey@localhost -p 1234Ctrl + L puis ssh://rey@localhost:1234
Bien entendu il est possible de mapper un port local avec un port autre que 22 sur la machine distante. Par exemple, si l'on souhaite accéder à un serveur Web présent sur une machine du réseau rpbs :
ssh -L9876:172.27.7.111:80 rey@epervier.rpbs.univ-paris-diderot.fr
Puis, dans un navigateur Web, taper dans la barre d'adresse : http://localhost:9876
La forge Gitlab est située à l'adresse https://gitlab.rpbs.univ-paris-diderot.fr.

L'authentification sur les dépôts de la forge peut s'effectuer par https en tapant ses identifiants à chaque fois ou par ssh par un système de clé publique / clé privée si vous vous connectez à partir du réseau bfa-cmpli. Dans le second cas il est nécessaire de copier sa clé publique sur son espace personnel :
cat ~/.ssh/id_rsa.pub
Puis aller dans Profile Settings -> SSH Keys -> ADD SSH KEY et copier / coller le contenu de la clé dans la fenêtre Key. Valider en cliquant sur ADD KEY.
Dans un terminal, taper :
git clone https://gitlab.rpbs.univ-paris-diderot.fr/rey/mon_depot.git
Depuis le réseau bfa-cmpli, dans un terminal, taper :
git clone git@172.27.7.118:rey/mon_depot.git
Sur la page d'accueil, cliquer sur + NEW PROJECT, renseigner les champs, puis cliquer sur CREATE PROJECT. Puis, dans un terminal :
Dans un terminal, taper :
cd dossier_du_projet git init git remote add origin https://gitlab.rpbs.univ-paris-diderot.fr/rey/mon_depot.git git add . git commit git push -u origin master
Depuis le réseau bfa-cmpli, dans un terminal, taper :
cd dossier_du_projet git init git remote add origin git@172.27.7.118:rey/mon_depot.git git add . git commit git push -u origin master
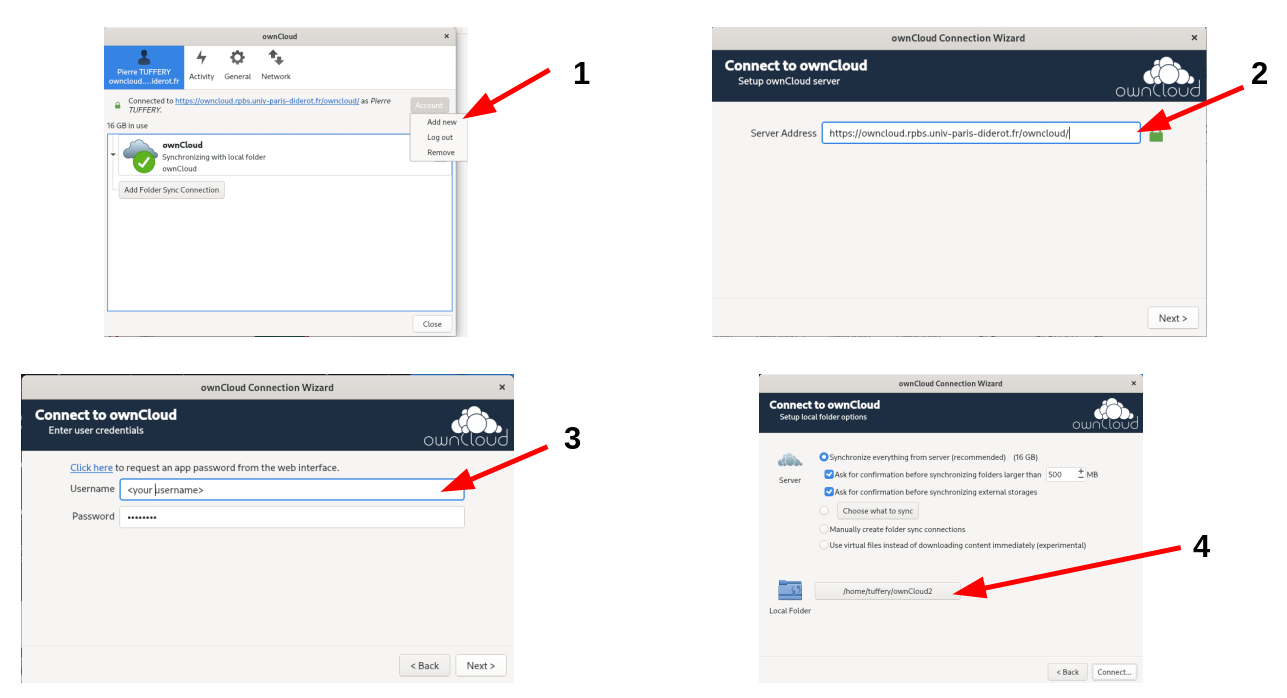
Une plate-forme de stockage et de partage de fichiers Owncloud est située à l'adresse https://owncloud.rpbs.univ-paris-diderot.fr.
La page d'accueil est on ne peut plus simple et permet un accès direct aux fichiers personnels et partagés. Il est possible de partager un fichier personnel avec d'autres personnes en cliquant sur l'icône Partager : on peut alors soit entrer le nom d'un autre utilisateur ou d'un groupe de la plate-forme (cmpli, équipe 1, équipe 2, équipe 3, système, etc...), soit partager sous forme de lien à transmettre à n'importe qui. Dans ce cas il est possible de protéger le lien à l'aide d'un mot de passe.
En cliquant sur le menu déroulant en haut à gauche, on a également accès à d'autres fonctions comme un calendrier qui permet de noter ses congés ou des réunions et qui ne pourra être visible que par les personnes de son choix.

Dans l'interface Web, cliquer sur Paramètres, puis copier l'adresse située sous WebDAV.
Dans Nautilus (Fichiers) : Ctrl + L puis coller l'adresse en substituant https par davs. Par exemple :
davs://owncloud.rpbs.univ-paris-diderot.fr:443/owncloud/remote.php/dav/files/rey/
Puis rentrer son login et mot de passe. On peut ensuite effectuer des glisser / déposer de fichiers comme dans un répertoire local.
Pour les distributions Debian/Ubuntu :
sudo apt-get install davfs2
Il s'agit d'une commande mount classique :
sudo mount.davfs https://owncloud.rpbs.univ-paris-diderot.fr/owncloud/remote.php/dav/files/rey /mnt/
Pour les distributions Debian/Ubuntu :
sudo apt-get install owncloud-client
Pour la distribution Fedora :
sudo dnf install owncloud-client
Pour OS X : voir https://owncloud.com/client/
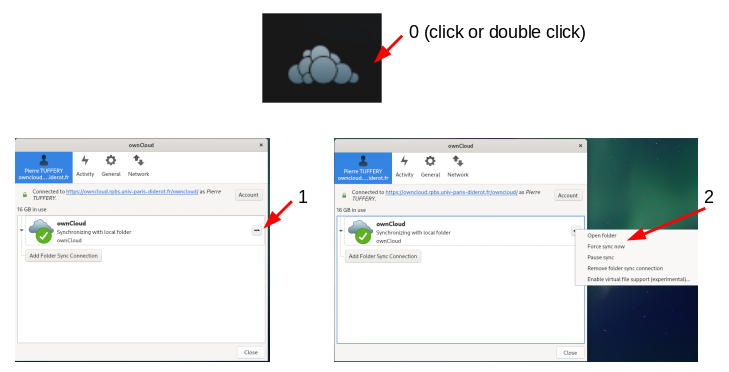
Selon la distribution et la configuration, le client peut ne pas lancer la synchronisation des fichiers de façon automatique. Dans ce cas, il est possible de forcer la synchronisation manuellement :
Une image est un template à partir duquel on va exécuter des conteneurs.
Lister les images présentes sur sa machine :
docker images
Chercher des images hébergées sur le registre officiel Docker :
docker search centos # exemple d'une recherche d'une distribution centos docker search gitlab # exemple d'une recherche d'un serveur gitlab
Lister les images hébergées sur le registre de développement du laboratoire :
docker search dev-registry.rpbs.univ-paris-diderot.fr/library
Lister les images hébergées sur le registre de production du laboratoire :
docker search docker-registry.rpbs.univ-paris-diderot.fr/library
Télécharger une image sur sa machine depuis le registre officiel Docker :
docker pull debian:stable
Télécharger une image sur sa machine depuis le registre de production du laboratoire :
docker pull docker-registry.rpbs.univ-paris-diderot.fr/opendocking
Pour renommer une image locale :
docker tag [ID DE L'IMAGE] [NOUVEAU NOM DE L'IMAGE]
Pour effacer une image locale :
docker rmi [ID DE L'IMAGE]
Un conteneur est une instance d'exécution créée à partir d'un template (image).
Démarrer un conteneur en mode intéractif à partir d'une image :
docker run -it debian:stable /bin/bash
En mode intéractif, le prompt du shell est modifié et affiche désormais l'identifiant du conteneur en cours d'exécution.
root@29d4663f7b11:~# _
Le conteneur se comporte de la même façon qu'une machine virtuelle. L'utilisateur est administrateur de cette machine (compte root), il est alors possible de réaliser des installations ou de modifier des fichiers sytème sans aucune incidence sur la machine hôte.
Pour sortir / couper le conteneur :
exit
ou encore :
Ctrl + D
Pour lister les conteneurs (y compris ceux qui ont été stoppés) :
docker ps -a
Pour redémarrer un conteneur qui a été stoppé :
docker start -a -i [ID DU CONTENEUR]
Pour effacer un conteneur stoppé :
docker rm [ID DU CONTENEUR]
Démarrer un conteneur en mode intéractif avec les bons uid et gid, en montant le dossier courant et en se plaçant dedans, et supprimer le conteneur à la sortie :
docker run -it --rm -v $(pwd):$(pwd) -u $(id -u):$(id -g) -w $(pwd) debian /bin/bash
Effacer les conteneurs arrêtés :
docker ps -qa -f "status=exited" | xargs docker rm
Effacer les images untagged (<none>) :
docker images --filter "dangling=true" -q --no-trunc | xargs docker rmi -f
Le Dockerfile est un fichier texte qui inclut une liste d'actions à exécuter pour construire une image.
Voici les différentes instructions à fournir :
FROM debian:jessie
LABEL maintainer="jean.dupont@u-paris.fr" LABEL principal.investigator="sophie.lemarchand@inserm.fr" LABEL contributors="marie.boulanger@u-paris.fr; francois.martin@inserm.fr; leila.belkacem@cea.fr"
docker inspect image:version --format={{json .Config.Labels}} ou module whatis image:versionENV PATH /usr/local/some_program/bin:$PATH
COPY src /tmp/ COPY test /test
RUN apt-get -q -y update && \ apt-get install -q -y \ python-pip \ python-dev \ r-base && \ apt-get autoremove -q -y && \ apt-get clean && \ rm -rf /var/lib/apt/lists/*
Quelques autres commandes utiles :
Remarque : La commande donnée par l'instruction CMD peut être utilisée comme argument de la commande donnée avec l'instruction ENTRYPOINT. Exemple:
ENTRYPOINT ["/usr/bin/babel"] CMD ["--help"]
Les sous-modules permettent de gérer un dépôt Git comme un sous-répertoire d'un autre dépôt Git. Cela permet de cloner des dépôts dans le projet et de garder isolés les commits de ce dépôt.
Bien évidemment, le dépôt principal doit être initialisé.
git init
Pour ajouter un sous-module :
git submodule add git@172.27.7.118:src/PyPDB.git src/PyPDB
ou :
git submodule add ../src/PyPDB.git src/PyPDB
Ne pas oublier de tracker le fichier .gitmodules nouvellement créé :
git add .gitmodules
Pour tirer la dernière version du sous-module :
git submodule update --remote
Ne pas oublier de refaire un commit du dépôt Git principal pour que Git mette à jour les pointeurs vers les sous-modules.
Taper la commande suivante :
docker build -t [NOM DE L'IMAGE] [CHEMIN VERS LE DOSSIER CONTENANT LE DOCKERFILE]
Exemple :
docker build -t mon_image .
C'est le moment de tester que tout fonctionne bien :
docker run -w /test --rm mon_image /bin/bash -c "source /test/.command"
Le dossier /scratch/user de l'utilisateur est automatiquement monté lorsqu'un conteneur est appelé avec la commande drun. L'écriture des fichiers de résultats doit donc se faire obligatoirement dans un sous-dossier du dossier courant. Tout fichier écrit en dehors de ce dossier sera effacé à la fin de l'exécution du conteneur (voir ci-dessous). Il est déconseillé d'utiliser des chemins absolus.
Il est conseillé d'écrire les fichiers temporaires directement dans le dossier /tmp du conteneur plutôt que dans le dossier courant. Chaque conteneur est automatiquement effacé après chaque exécution avec la commande drun.
Les conteneurs appelés par l'intermédiaire du portail Mobyle sont lancés en tant qu'utilisateur www-data. Certains logiciels écrivent dans le dossier home de l'utilisateur qu'il l'a lancé (pour www-data il s'agit de /var/www). Par défaut, les images de systèmes de base telles que debian ne comporte pas de dossier /var/www, ce qui risque d'entraîner des erreurs lors du lancement de ces programmes. Pour pallier à ce problème il est nécessaire de créer le dossier /var/www et de lui donner les bons droits :
RUN mkdir /var/www && chown 33:33 /var/www
Le déploiement d'une image docker se fait dorénavant à travers un mécanisme d'intégration continue via le gitlab RPBS. Chaque image docker possède un projet correspondant dans le groupe docker. Pour ajouter une nouvelle image :
git remote add origin https://gitlab.rpbs.univ-paris-diderot.fr/docker/mon-outil.git
ou :
git remote add origin git@172.27.7.118:docker/mon-outil.git
Et créer une branche de développement :
git checkout -b 1.0-dev git add . git commit -m "Initial commit." git push -u origin 1.0-dev
nom_du_projet:nom_de_la_branche, par exemple : mon-outil:1.0-dev. Les images avec un tag se terminant par -dev sont tirées depuis le registre avant chaque exécution. Pour les autres, la mise à jour est quotidienne.